1.DataFrame基本介绍
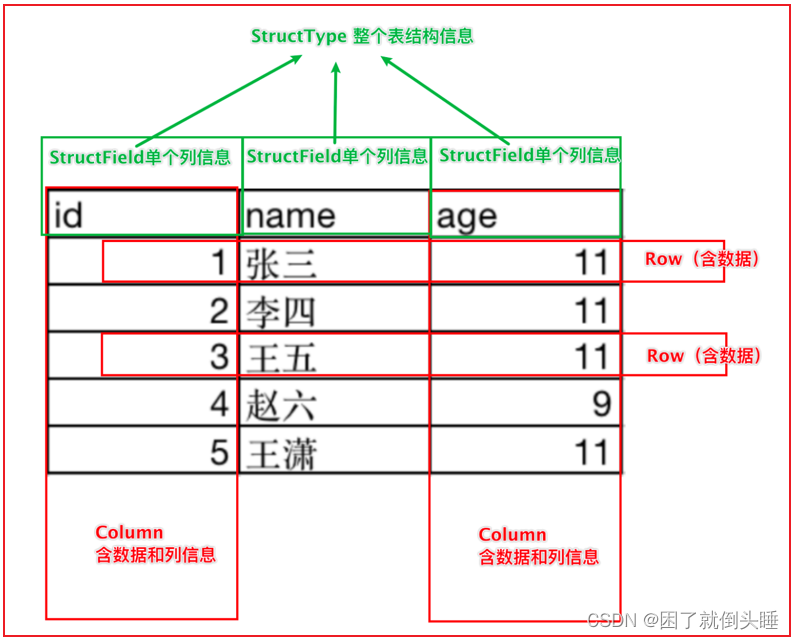
DataFrame表示的是一个二维的表。二维表,必然存在行、列等表结构描述信息 表结构描述信息(元数据Schema): StructType对象 字段: StructField对象,可以描述字段名称、字段数据类型、是否可以为空 行: Row对象 列: Column对象,包含字段名称和字段值 在一个StructType对象下,由多个StructField组成,构建成一个完整的元数据信息
如何构建表结构信息数据:

2.DataFrame的构建方式
方式1: 使用SparkSession的createDataFrame(data,schema)函数创建
data参数
1.基于List列表数据进行创建
2.基于RDD弹性分布式数据集进行创建
3.基于pandas的DataFrame数据进行创建
schema参数
1: 字符串
格式一 :“字段名1 字段类型,字段名2 字段类型”
格式二(推荐):“字段名1:字段类型,字段名2:字段类型”
2: List
格式: ["字段名1","字段名2"]
3: DataType(推荐,用的最多)
格式一:schema=StructType().add('字段名1',字段类型).add('字段名2',字段类型)
格式二:schema=StructType([StructField('字段名1',类型),StructField('字段名1',类型)])
方式2: 使用DataFrame的toDF(colNames)函数创建
DataFrame的toDF方法是一个在Apache Spark的DataFrame API中用来创建一个新的DataFrame的方法。这个方法可以将一个RDD转换为DataFrame,或者将一个已存在的DataFrame转换为另一个DataFrame。在Python中,你可以使用toDF方法来指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。
格式: rdd.toDF([列名])
方式3: 使用SparkSession的read()函数创建
在 Spark 中,SparkSession 的 read 是用于读取数据的入口点之一,它提供了各种方法来读取不同格式的数据并将其加载到 Spark 中进行处理。
统一API格式:
spark.read
.format('text|csv|json|parquet|orc|...') : 读取外部文件的方式
.option('k','v') : 选项 可以设置相关的参数 (可选)
.schema(StructType | String) : 设置表的结构信息
.load('加载数据路径') : 读取外部文件的路径, 支持 HDFS 也支持本地
简写API格式:
注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写
格式: spark.read.文件读取方式()
注意: parquet:是Spark中常用的一种列式存储文件格式和Hive中的ORC差不多, 他俩都是列存储格式
2.1 createDataFrame()创建
场景:一般用在开发和测试中。因为只能处理少量的数据
2.1.1 基于列表
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
# 2.创建DF对象
data = [(1, '张三', 18), (2, '李四', 28), (3, '王五', 38)]
df1 = spark.createDataFrame(data,schema=['id','name','age'])
# 展示数据
df1.show()
# 查看结构信息
df1.printSchema()
print('---------------------------------------------------------')
df2 = spark.createDataFrame(data,schema='id int,name string,age int')
# 展示数据
df2.show()
# 查看结构信息
df2.printSchema()
print('---------------------------------------------------------')
df3 = spark.createDataFrame(data,schema='id:int,name:string,age:int')
# 展示数据
df3.show()
# 查看结构信息
df3.printSchema()
# 3.关闭资源
spark.stop()
2.1.2 基于RDD普通方式
场景:RDD可以存储任意结构的数据;而DataFrame只能处理二维表数据。在使用Spark处理数据的初期,可能输入进来的数据是半结构化或者是非结构化的数据,那么可以先通过RDD对数据进行ETL处理成结构化数据,再使用开发效率高的SparkSQL来对后续数据进行处理分析。
Schema选择StructType对象来定义DataFrame的“表结构”转换RDD
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 2.读取生成rdd
textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')
print(type(textRDD)) # <class 'pyspark.rdd.RDD'>
etlRDD = textRDD.map(lambda line:line.split(',')).map(lambda l:(l[0],l[1]))
# 3.定义schema结构信息
schema1 = StructType().add('name',StringType(),True).add('age',StringType(),True)
schema2 = StructType([StructField('name',StringType(),True),StructField('age',StringType(),True)])
schema3 = ['name','age']
schema4 = 'name string,age string'
schema5 = 'name:string,age:string'
# 4.创建DF对象
dfpeople = spark.createDataFrame(etlRDD,schema5)
# 5.df展示结构信息
dfpeople.show()
dfpeople.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
dfpeople.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 7.关闭资源
sc.stop()
spark.stop()
2.1.3 基于RDD反射方式
Schema使用反射方法来推断Schema模式Spark SQL 可以将 Row 对象的 RDD 转换为 DataFrame,从而推断数据类型。
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Row
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 2.读取生成rdd
# 3.定义schema结构信息
textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')
etlRDD_schema = textRDD.map(lambda line:line.split(',')).map(lambda l:Row(name=l[0],age=l[1]))
# 4.创建DF对象
dfpeople = spark.createDataFrame(etlRDD_schema)
# 5.df展示结构信息
dfpeople.show()
dfpeople.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
dfpeople.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 7.关闭资源
sc.stop()
spark.stop()
2.2 toDF()创建
schema模式编码在字符串中,toDF参数用于指定列的名字。如果你不指定列的名字,那么默认的列的名字会是_1, _2等等。
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Row
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 2.读取生成rdd
# 3.定义schema结构信息
textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/data1.txt')
etlRDD = textRDD.map(lambda line:line.split(','))
# 4.创建DF对象
dfpeople = etlRDD.toDF(['name','age'])
# 5.df展示结构信息
dfpeople.show()
dfpeople.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
dfpeople.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 7.关闭资源
sc.stop()
spark.stop()
2.3 read读取外部文件
复杂API
统一API格式:
spark.read
.format('text|csv|json|parquet|orc|avro|jdbc|.....') # 读取外部文件的方式
.option('k','v') # 选项 可以设置相关的参数 (可选)
.schema(StructType | String) # 设置表的结构信息
.load('加载数据路径') # 读取外部文件的路径, 支持 HDFS 也支持本地
简写API
请注意: 以上所有的外部读取方式,都有简单的写法。spark内置了一些常用的读取方案的简写 格式: spark.read.读取方式() 例如: df = spark.read.csv( path='file:///export/data/_03_spark_sql/data/stu.txt', header=True, sep=' ', inferSchema=True, encoding='utf-8', )
2.3.1 Text方式读取
text方式读取文件: 1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理 2- 默认生成的列名叫value,数据类型string 3- 只能够在schema中修改字段value的名称,其他任何内容不能修改
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Row
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
# 2.读取数据
# 注意: 读取text文件默认只有1列,且列名交value,可以通过schema修改
df = spark.read\
.format('text')\
.schema('info string')\
.load('file:///export/data/spark_project/spark_sql/data/data1.txt')
# 5.df展示结构信息
df.show()
df.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
df.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 6.关闭资源
spark.stop()
2.3.2 CSV方式读取
csv格式读取外部文件: 1- 复杂API和简写API都必须掌握 2- 相关参数作用说明: 2.1- path:指定读取的文件路径。支持HDFS和本地文件路径 2.2- schema:手动指定元数据信息 2.3- sep:指定字段间的分隔符 2.4- encoding:指定文件的编码方式 2.5- header:指定文件中的第一行是否是字段名称 2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Row
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
# 2.读取数据
# 注意: csv文件可以识别多个列,可以使用schema指定列名,类型
# 原始方式
# df = spark.read\
# .format('csv')\
# .schema('name string,age int')\
# .option('sep',',')\
# .option('encoding','utf8')\
# .option('header',False)\
# .load('file:///export/data/spark_project/spark_sql/data/data1.txt')
# 简化方式
df = spark.read.csv(
schema='name string,age int',
sep=',',
encoding='utf8',
header=False,
path='file:///export/data/spark_project/spark_sql/data/data1.txt'
)
# 5.df展示结构信息
df.show()
df.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
df.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 7.关闭资源
spark.stop()
2.3.3 JSON方式读取
json读取数据: 1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充 2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
json的数据内容
{'id': 1,'name': '张三','age': 20}
{'id': 2,'name': '李四','age': 23,'address': '北京'}
{'id': 3,'name': '王五','age': 25}
{'id': 4,'name': '赵六','age': 29}
代码实现
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
from pyspark.sql.types import StructType, StringType, StructField, Row
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
# 2.读取数据
# 注意: json的key和schema指定的字段名不一致,会用null补充,如果没有数据也是用null补充
# 简化方式
df = spark.read.json(
schema='id int,name string,age int,address string',
encoding='utf8',
path='file:///export/data/spark_project/spark_sql/data/data2.txt'
)
# 5.df展示结构信息
df.show()
df.printSchema()
# 6.拓展: 创建临时视图,方便sql查询
df.createTempView('peoples')
r = spark.sql('select * from peoples')
r.show()
# 关闭资源
spark.stop()